|

Número 0: Sistemas de gestão de memórias de tradução
A tradução automática: Passado, presente e futuro
Karl Heinz Freigang, Universidade de Saarlandes, Saarbrücken
|
Introdução
As primeiras tentativas realizadas no âmbito da "automatização" do processo de tradução entre línguas naturais tiveram lugar em meados do século XVII na cidade alemã de Speyer, quando o monge Johannes Becher escreveu um documento sobre a invenção de uma metalinguagem matemática desenhada para descrever o significado de frases escritas em qualquer língua.
Essa metalinguagem, que consistia em atribuir sequências de números ao significado das palavras, e alguns números para expressar a semântica das desinências flexionais, era acompanhada de listas de equações que davam expressões matemáticas de significado a palavras em alemão e latim, por exemplo. As frases numa dessas línguas poderiam ser traduzidas para uma outra língua de forma "mecânica" através destas equações.
As primeiras "máquinas" para a tradução mecânica foram inventadas entre 1930 e 1940 por Georges Artsruni, um engenheiro francês (inventor do "Cérebro Mecânico") e pelo engenheiro russo P. Trojanskij que inventaram, isoladamente, aparelhos mecânicos para o scanning de uma banda perfurada com expressões numa língua natural e para relacionar essas "palavras" com palavras de outra língua contidas numa segunda banda perfurada.
|

Fig. 1: Fac-símile da capa do documento
|
|
|
|
Só depois da Segunda Guerra Mundial, no final da década de 40, quando as primeiras grandes máquinas calculadoras começaram a ser usadas em matemática, é que os cientistas começaram a pensar que essas máquinas poderiam ter um uso além do numérico e poderiam servir, por exemplo, para decodificar mensagens codificadas ou para passá-las para a língua natural. No seu famoso Memorando para a Fundação Rockefeller em 1949, Warren Weaver fez a sua conhecida analogia entre tradução e decodificação:
|
|
"Tenho um texto escrito em russo mas vou fazer de conta que está escrito em inglês e que foi codificado com símbolos estranhos. Só é preciso extrair a codificação para recuperar a informação contida no texto."
|
|
|
Contudo, nos anos seguintes, a tradução automática tornou-se mais complicada. Não se tratava simplesmente de relacionar um código ou um símbolo com outro, mas de organizar o significado gramatical e semântico da língua para poder traduzir de uma língua para outra (pode-se encontrar mais informação sobre a tradução automática em Hutchins, 1986).
|
|
De Georgetown ao ALPAC
A primeira demonstração de um sistema de tradução automática que teve "sucesso" aconteceu no dia 7 de Janeiro de 1954 na Universidade de Georgetown, em Washington D.C. Foi implantado um sistema de tradução do russo para o inglês num mainframe IBM que continha um dicionário bilingue com aproximadamente 250 entradas. O sistema conseguiu traduzir com êxito um corpus de 60 frases simples em russo por um processo de substituição palavra por palavra, e com algumas regras adicionais para conseguir a ordem correcta das palavras em inglês.
|
|
Os resultados da experiência foram considerados uma prova da viabilidade da tradução automática e, nesse período, alguns pesquisadores estavam convencidos de que o sucesso da tradução automática apenas consistia na construção de imensos dicionários. A "tradução totalmente automática de alta qualidade" era o objectivo que se tentaria alcançar nos anos seguintes.
|
|
Dez anos depois, aproximadamente, o governo americano criou uma comissão para analisar o mercado da tradução e conhecer as últimas novidades em relação à pesquisa e ao desenvolvimento realizados no âmbito da tradução automática. Este Comité de Assessoria no Processo da Automatização de Línguas publicou um relatório em 1966, o conhecido Relatório ALPAC, que passou a ser conhecido como o "Livro preto da tradução automática", também por causa da capa preta do documento. A Comissão chegou à conclusão de que não havia necessidade de dar apoio à pesquisa e ao desenvolvimento da tradução automática e que era mais importante investir na melhoria da qualidade da tradução tradicional que realizavam os tradutores humanos:
|
|
"Contudo, o comité não justifica suficientemente um apoio de envergadura à tradução automática per se, considerando que este tipo de tradução é mais lenta, menos precisa e mais cara do que a realizada pelos tradutores humanos..." (ALPAC 1966)
|
|
|
Como consequência desse relatório, os fundos do governo dos EUA para a tradução automática foram suspendidos praticamente na sua totalidade. Na Europa, havia alguns projectos de pesquisa, como por exemplo na Universidade de Grenoble, em França, e na Universidade de Saarbrücken, na Alemanha. A partir da segunda metade da década de 70 a pesquisa e o desenvolvimento foram reiniciados nos EUA e especialmente no Japão, onde o seu desenvolvimento foi aumentando a partir da década de 80 a par do desenvolvimento dos microcomputadores.
|
|
A situação actual
Não obstante, pesquisadores de todo o mundo acharam que o ambicioso objectivo da "Tradução totalmente automática de alta qualidade" não pode ser atingido num futuro próximo e começaram a pôr de lado os sistemas de tradução automática para se concentrarem no desenvolvimento de ferramentas de ajuda ao tradutor.
|
|
O rápido desenvolvimento do hardware e do software nos últimos anos fez com que a tradução profissional hoje em dia não seja possível sem a ajuda de diferentes ferramentas de tradução. Todo o processo de tradução pode ser realizado de uma forma muito mais cómoda graças ao uso da diversidade de soluções em software existentes, tanto no que diz respeito à pesquisa de terminologia e de informação adicional no início do projecto de tradução, como para a ajuda na redacção e na edição, ou ainda para a gestão do projecto e dos dados relativos ao cliente.
|
|
A pesquisa de terminologia e informação adicional
As bibliotecas eram os lugares onde era comum procurar terminologia e informação adicional sobre o assunto do projecto de tradução, tanto as públicas como as privadas. Na actualidade, a Internet permite o acesso a informação através de motores de pesquisa e de bases de dados terminológicas em linha; em muitos casos, permite ainda conseguir informação em bases de dados de corpora completos. Existe um grande número de sítios na rede especializados na informação e links de recursos terminológicos e de outros sítios importantes para a tradução, por exemplo:
- Fórum de Terminologia da Universidade de Vaasa (http://www.uwasa.fi/comm/termino/) com links para muitas bases de dados terminológicas e dicionários.
- Portal de terminologia do Instituto de Tradução e Interpretação da Universidade de Innsbruck (http://www2.uibk.ac.at/translation/) com informação muito útil sobre terminologia na Internet.
- EURODICAUTOM, a base de dados terminológica da Comissão da União Europeia, que é de acesso gratuito na rede (http://europa.eu.int/eurodicautom/Controller).
- Sítio do Departamento de Linguística Aplicada, da Faculdade de Tradução e Interpretação da Universidade de Saarland, com um grande número de links relacionados com a tradução (http://fr46.uni-saarland.de/index.php?id=252) de outros centros académicos, organizações profissionais, centros de língua, etc.
- Sítios da Federação Internacional de Tradutores (FIT) (http://www.fit-ift.org) e de organizações nacionais, como a alemã Bundesverband der Dolmetscher und Übersetzer (BDÜ) (http://www.bdue.de) .
|
|
Outras fontes de informação e de oportunidades de intercâmbio de experiências e de conhecimento entre tradutores são os fóruns na Internet, de fácil inscrição e que oferecem a possibilidade de tratar uma ampla diversidade de assuntos relacionados com a tradução, por exemplo:
|
|
Edição multilingue e processamento de texto
Os sistemas de edição e de processamento de textos a serem usados no processo de tradução devem oferecer a possibilidade de editar e de introduzir textos em todos as línguas com que o tradutor trabalhe. Há alguns anos, quando se usavam os tradicionais conjuntos de caracteres de 8 bits (ASCII ou ANSI), só havia 256 caracteres diferentes, e se o tradutor precisava de trabalhar com línguas não latinas como o russo ou o grego, era preciso deslocar-se entre páginas com uma codificação diferente. Hoje em dia, os modernos sistemas de Windows oferecem a possibilidade de usar o Unicode, que na sua versão de 16 bits oferece mais de 65 mil caracteres diferentes num conjunto de um carácter. Assim, o tradutor só precisa de instalar as línguas oferecidas pelo Windows e pode passar de uma configuração de teclado para outra num mesmo documento. Os sistemas de processamento de texto multilingue actuais também admitem formatos específicos para cada país, para datas, moedas, unidades de medida, etc.
|
|
Gestão terminológica
A terminologia tem um papel muito importante na tradução de textos de especialidade. Além da terminologia que se pode encontrar em dicionários ou bases de dados on line, os tradutores devem compilar e administrar a informação terminológica de diversas fontes, por exemplo a recompilação de terminologia realizada pelos próprios clientes ou por outros colegas. Essa informação terminológica deve ser importada para as bases de dados terminológicas personalizadas que são administradas mediante sistemas especiais de gestão terminológica. Com o objectivo de se conseguir usar essa terminologia, inclusive durante a edição da tradução num sistema de processamento de texto, instalam-se as interfaces entre o sistema terminológico e o processador de texto, permitindo ao tradutor a procura de termos na base de dados, a partir do processador de texto, bem como copiar traduções da base de dados para o texto.
|
|
Existem diferentes tipos de sistemas de gestão terminológica no mercado que diferem na complexidade das entradas, no número de línguas ou de pares de línguas que podem ser armazenados numa base de dados, e na flexibilidade da estrutura de uma entrada, oferecendo assim a possibilidade de criar, por exemplo, uma estrutura de entradas personalizada.
|
|
Um exemplo de sistema de gestão terminológica com uma estrutura de entradas complexa e pré-definida, permitindo a gestão terminológica multilingue centrada no conceito, é o sistema TermStar da STAR AG (http://www.star-group.net). A figura 2 mostra a edição da estrutura de uma entrada do TermStar.
|
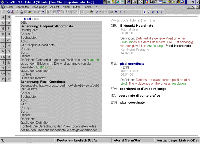 Fig. 2: Entrada do TermStar
Fig. 2: Entrada do TermStar
(Clique na imagem para obter uma ampliação)
|
|
Um exemplo de sistema de gestão terminológico que permite que o utilizador defina a sua própria estrutura de entrada é o Multiterm da Trados GmbH (http://www.trados.com).
|
|
Neste sistema, os utilizadores podem definir as categorias de dados que querem usar, diferenciando entre "campos de índice" (línguas e outras categorias que serão utilizadas para classificar as entradas), "campos de texto" (categorias como definição, contexto, etc. que contêm texto mais ou menos longo) e "campos de atributo" (categorias com valores fixos e predefinidos, por exemplo a categoria gramatical, etc.). A figura 3 mostra um exemplo das categorias de dados personalizadas do Multiterm.
|
 Fig. 3: Categorias de dados personalizadas no Multiterm
Fig. 3: Categorias de dados personalizadas no Multiterm
(Clique na imagem para obter uma ampliação)
|
|
Com o objectivo de compilar terminologia, têm sido desenvolvidos diferentes softwares que tentam extrair terminologia monolingue ou bilingue de corpora existentes. No caso da extracção de terminologia bilingue, os respectivos textos da língua de origem e da língua de chegada devem estar alinhados antes de serem processados pelas ferramentas de extracção terminológica, de maneira a que haja uma relação entre os segmentos (frases) na língua de origem e de chegada que contenham os termos. Quando se extraem termos de textos monolingues, pode-se usar uma base de dados terminológica já existente durante a extracção e assim excluirem-se termos já existentes na base de dados. A figura 4 mostra uma lista de termos extraídos de um documento monolingue com "termos excluídos" que já estão presentes na sua respectiva base de dados no Multiterm; a ferramenta para realizar a extracção é o ExtraTerm da TRADOS GmbH.
|
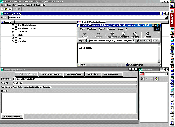
Fig. 4: Lista monolingue de termos extraída pelo ExtraTerm
(Clique na imagem para obter uma ampliação)
|
|
Ferramentas da memória de tradução
Na maioria dos casos, estes sistemas de gestão terminológica são um dos componentes de um ambiente integrado de tradução que, além da base de dados terminológica, contém um editor para introduzir e editar a tradução, e um software para reciclar traduções anteriores de textos similares na mesma língua de origem. Estas "memórias de tradução" são usadas durante o processo de tradução para procurar unidades de tradução ("segmentos", especialmente frases) que são idênticas ou similares aos segmentos que devem ser traduzidos. O material contido na memória de tradução, por exemplo os textos no idioma de origem e sua tradução, está organizado em pares de segmentos ("frases" numa base de dados de frases bilingue ou como pares de "textos de referência" nos quais as frases na língua de origem e de destino são associadas entre si. Os algoritmos de pesquisa não se limitam a procurar os segmentos idênticos, também procuram os segmentos que têm alguma semelhança. Quando se traduz um texto novo usando uma memória de tradução, todas as unidades de tradução podem ser armazenadas na memória e reutilizadas quando apareçam unidades iguais ou similares, seja no mesmo documento ou noutro.
|
|
Um exemplo de ambiente integrado de tradução é o TRADOS Translator's Workbench, que usa o Word como editor e o Multiterm como base de dados terminológica (Fig. 5). Neste sistema os segmentos completos da memória de tradução aparecem na parte superior da tela, enquanto os termos simples ou compostos podem ser encontrados no Multiterm e aparecem no canto superior direito da tela.
|

Fig. 5: O TRADOS Workbench tem um amplo segmento
no Word e na memória de tradução
(Clique na imagem para obter uma ampliação)
|
|
No sistema Déjà Vu da Atril, Espanha (http://www.atril.com) os algoritmos de pesquisa não se limitam a procurar segmentos completos (frases) mas também as chamadas "porções", que, geralmente, são grupos de palavras ou cláusulas. Por isso, inclusive nos casos em que não há correspondência alguma entre o segmento completo (frase) na base de dados da memória de tradução, o Déjà Vu tenta "agrupar" uma tradução a partir de "porções" identificadas na memória e de termos da base de dados. O editor do Déjà Vu está organizado em forma de tabela com os segmentos na língua de origem no lado esquerdo e as traduções na coluna direita; os resultados da informação encontrada na memória de tradução são mostrados na parte inferior da tela, e as porções e a terminologia encontrada são mostradas no lado direito da tela (Fig. 6).
|

Fig. 6: Déjà Vu com o editor, os resultados da memória
de tradução, as porções e a terminologia
(Clique na imagem para obter uma ampliação)
|
|
O uso de "porções" e a ferramenta de agrupamento no Déjà Vu tornam este sistema parecido com os sistemas de tradução assistida, também designados sistemas de tradução automática baseados em exemplos. Em vez de tentar implantar uma análise linguística exaustiva num sistema de tradução automática, esta abordagem tenta fundamentar o processo de tradução automática num imenso conjunto de "exemplos de tradução", estruturados, por exemplo, segundo os tipos de locuções (locuções substantivas, verbais, etc.).
|
|
A tradução automática hoje
A tradução automática "baseada em exemplos" ainda está em desenvolvimento e não há nenhum sistema de tradução automática no mercado que a use, embora alguns sistemas tentem usar a tecnologia da memória de tradução. Estes sistemas, como o Langenscheidt T1 (http://www.langenscheidt.de/deutsch/index.html) ou o Personal Translator da Linguatec (http://www.linguatec.de/topics/mt2001.shtml) combinam a abordagem tradicional da tradução automática (T1, antes METAL, desenvolvido Pela Universidade de Austin e pela Siemens e a Personal Translator, antes LMT desenvolvido pela IBM) com o conceito de memória de tradução. Antes de processar uma frase com uma análise linguística, estes sistemas podem procurar a frase completa na memória de tradução ("arquivo de tradução"); apenas no caso de não existir nenhuma frase similar na memória, começa a análise linguística.
|
|
Tal como estes dois sistemas que têm sua origem nos primeiros programas de tradução automática, existem outros sistemas disponíveis; trata-se de antigos sistemas de tradução para mainframe adaptados para o microcomputador. Um dos gigantes da tradução automática, o SYSTRAN, que ainda é usado na Comissão Europeia e em outras instituições, pode ser encontrado em diferentes versões - SYSTRAN pessoal, profissional e empresarial -, e funciona com o Windows NT/2000 (http://www.systransoft.com). O Power Translator é o antigo sistema de tradução para microcomputador derivado do sistema Georgetown, o Globalink, e trata-se de um software para Windows
(http://www.bmsoftware.com/powertranslator.htm).
|
|
Além destes sistemas para microcomputador, há ainda sistemas de tradução automática para mainframe ou para o sistema operativo UNIX. O SYSTRAN, como já foi mencionado, ainda é usado na Comissão Europeia, e oferece traduções aproximadas, que geralmente só são utilizadas com fins informativos. O TAUM METEO, desenvolvido na Universidade de Montreal, é um software que tem sido usado durante várias décadas para traduzir a previsão meteorológica de inglês para francês no Centro de Meteorologia Canadiano. Estas previsões contêm um vocabulário muito restrito e pouca diversidade de estruturas linguísticas; o METEO tem sido melhorado para trabalhar com este tipo de linguagem tão limitada.
|
|
Conclusão
Contudo, hoje em dia, as ferramentas de tradução assistida são indispensáveis para o trabalho do tradutor. Embora a capacidade linguística dos sistemas de tradução automática não tenha melhorado muito nas duas últimas décadas, as memórias de tradução e as ferramentas de gestão terminológica estão muito disseminadas entre os profissionais dedicados à tradução técnica, que trabalham com textos especializados e muito repetitivos, e que requerem frequentes actualizações e uma terminologia coerente.
|
|
Mas não é unicamente o processo da tradução, no sentido de automatização da palavra, que está a crescer constantemente, também o processo de pesquisa e de reutilização de informação está dominado pela informática, sendo a Internet a ferramenta mais importante e mais usada, inclusive como método de comunicação entre os tradutores e os clientes e para administrar o projecto.
|
|
O uso eficaz de todas as ferramentas de tradução pode requerer uma reorganização do trabalho do tradutor. Dado que os erros cometidos na fase inicial da introdução das ferramentas no ambiente de trabalho podem ter consequências terríveis posteriormente, é recomendável investir algumas horas, ou mesmo alguns dias, na familiarização das ferramentas antes de as usar num projecto de tradução. Existem cursos de formação oferecidos pelos distribuidores do software, pelas organizações profissionais e pelos centros de formação.
|
Bibliografia |
|
Hutchins, W.J. (1986): Machine Translation: Past, Presence, Future. Ellis Horwwod/Wiley, Chichester/New York.
|
|
ALPAC (1966): Languages and Machines. Computers in Translation and Linguistics. A Report by the Automatic Language Processing Advisory Committee, Division of Behavioral Sciences, National Academy of Sciences, National Research Council. Washington, D.C.
|
|
Outubro 2001
|
|
